今天讲一个我在面试应届生时遇到的小故事:
应该是去年年初,一位应届毕业生来面试实习,我想既然是实习那就可以放点水咯...就想先问他一些简单的问题吧。
于是我们就开始面试了。
我:“简历中你说自己对数据安全有独特的见解,你能不能举一些数据安全方面的例子?”
A:“师傅好,这没问题!我在写后端的时候,涉及到用户管理模块,当我在数据库的用户表中存储密码时,就需要在存储前加密。”
我:“你确定是加密?而不是什么其他的形式吗?”
A:“是的。”
我:“那你把加密密钥存在哪?”
A:“什么密钥?”
我:“你用来加密密码的密钥啊?你用的是对称加密还是非对称加密?用户是独享每个密钥还是共享一个密钥?”
A:“emm...好像记错了,我用的是哈希。”
我:“OK,没事,我们继续。说到哈希,你能解释一下为什么我们需要在存储前对密码进行哈希处理,而不是直接存储明文密码吗?”
A:“因为我们想要确保数据的安全性,当需要验证密码时,密码肯定不能以明文形式从前端发送到服务器进行验证吧?”
我:“那当你注册用户时,你需要以明文形式发送密码和确认密码吗?”
A:“emm,应该会吧,但我只发一次明文密码。”
我:“哦...所以我是不是可以这样理解,你认为在数据库中存储哈希是为了避免在 API 调用过程时以明文形式发送敏感数据?”
A:“是这样。”
我:“那么你认为在我们的数据库被入侵者攻破并带走数据后,把密码映射存储成哈希值有什么意义呢?”
A:“这样原始密码就不会暴露给黑客,他们只能拿到哈希值呀!”
我:“是的,但不只是这些吧。仍然可能有人使用彩虹表来做碰撞,通过碰撞就能得到原始密码了。你知道加盐吗?”
A:“听说过,盐值应该是一个随机字符串,这样会使密码存储更安全。”
我:“不错,那你能告诉我为什么会更安全吗?”
A:“emm...这就到我的知识盲区了...”
我:“假设有人通过注入或其他方式获得了数据库,然后他使用彩虹表来试图破解密码,如果这个时候确实发生了碰撞,入侵者可能获得了原始字符串,但他得到的值是混合了随机字符串(盐)的原始密码,通过这种做法这样我们可以防止真实密码被盗,也能阻止了一些人获取你的‘万能’密码来登录你的其他账户。”
A:“我明白了。”
我:“说回到你做的系统吧,你用什么算法来给你的用户密码做哈希呢?”
A:“md5肯定是不安全的,所以我用了其他选项,比如sha3。”
我:“哦,挺好挺好,那你能简单说一下为什么 md5 不安全吗?为什么选择 sha3 来哈希密码?因为据我所知,sha3 通常用于文件指纹或者 JWT 令牌签名。”
A:“md5被证明不安全,已经有一些新闻报道了。至于为什么选择 sha3 嘛,我觉得第三代一定比第一代更安全。”
我:“这样啊,那新闻说 md5 不安全,但你知道为什么吗?”
A:“emm,不太清楚”
我:“简单来说,这是由于其抗哈希碰撞力比较弱,可能会被彩虹表攻击。”
A:“什么是彩虹表?”
我:“彩虹表是一种预先计算的表,包含由明文密码导出的哈希值链。这些链通过反复应用哈希函数和一系列还原函数生成。彩虹表通常用于密码破解攻击,攻击者将存储在被攻破数据库中的哈希密码与彩虹表中的条目进行比较,以找到匹配的明文密码。”
A:“哦...”
我:“所以你为什么使用 sha3 生成密码哈希?只是因为听起来更安全吗?”
A:“是...”
我:“额,确实可以这样理解,不过对于密码哈希来说,可能有更好的选项吧,比如 argon2。与 sha3 相比,argon2 需要更多的迭代和更高的内存,这意味着生成一个哈希值需要更高的时间复杂度和资源消耗,这使得攻击者更难进行暴力破解。而sha3通常用于其他目的,例如数字签名,在安全性和性能之间找平衡之类。”
...
接下来我们分析以上内容的细节吧。
密码哈希
我们都知道,已经4202年了,密码绝不应以明文形式保存。
但是,用哈希加盐的原因不仅仅是为了减少在API调用期间以明文形式发送密码的行文。主要的点是当数据库落入黑客手中时,这样做可以让他们无法恢复原始密码。因为如果他们靠碰撞拿到了真是密码,接下来发生的可能就要扫号了,他们可以用相同的用户名密码反复尝试在不同账户上使用,如邮箱、银行卡、社交媒体、学校甚至社保账户等。
为什么不使用加密而是哈希?
可逆性很重要。加密是一个可逆的过程,这意味着只要有正确的密钥,就可以恢复原始的明文密码。这就是很严重的风险,即使你号称加密密钥被安全的管理也很危险。此外,管理密码的加密密钥(如构建密钥链)会产生巨量成本和复杂度。
为什么需要盐值呢
盐值用于增加每个哈希密码的随机性,使得攻击者使用预计算表(如彩虹表)破解密码变得计算上变得很贵。如果没有盐值,攻击者可以通过将哈希值与一个大型彩虹表比较来高效地猜测密码。
此外,盐值必须对每个密码唯一,而不仅仅是每个用户唯一。这确保了即使两个用户有相同的密码,由于独特的盐值,他们的哈希值也会不同,防止攻击者轻易识别重复的密码。
不同用途的哈希
SHA3 比 MD5 更安全,但为什么不使用 SHA3?哈希又不是只为用户密码设计出来的,它还有其他不同的用处:
数据完整性:SHA3 一般用于文件指纹,来校验其完整性,校验文件完整的算法需要在在速度和抗哈希碰撞之间取得一个平衡点。SHA3 既提供了优秀的抗碰撞性,又能在计算文件哈希中保持合理的性能。
校验:速度是最重要的,以 CRC32 为例,在网络传输期间验证数据完整性时,CRC32 等算法表现优异,CRC32 通常用于快速识别文件在传输过程中是否被修改,它优先考虑效率而不是碰撞抵抗。
密钥生成(例如,Argon2、bcrypt、PBKDF2):为了安全存储密码或生成加密密钥,首选专门的密钥派生函数(KDF)如 Argon2、bcrypt 或 PBKDF2,这些算法有意引入“慢”哈希过程,增加计算复杂性以抵抗哈希碰撞暴力破解。
虽然 SHA3 适用于诸如 HTTPS 连接或 JWT 令牌签名生成等任务,但它缺乏提供密码哈希所需的额外安全性的“慢”特性。
为什么 KDF 在哈希密码中很重要
密钥派生函数(KDFs)在密码哈希中起着至关重要的作用,它们通过有意减慢哈希过程来增强安全性。这种故意的减速是通过多次迭代哈希值计算实现的。虽然这些迭代的技术细节可能很复杂,但基本上涉及像移位、取反和异或(XOR)等重复操作,通常执行成千上万轮。
使用 KDFs 在密码哈希中的主要目标是:
减慢过程:通过引入计算开销,KDF 使得攻击者用暴力破解密码变得更困难。计算哈希值所需的时间和计算资源的增加,可以防止快速字典攻击或彩虹表攻击的作用。
资源消耗:KDF 在哈希过程中还会消耗大量的 CPU 和内存资源,这种资源密集型的特性进一步阻碍了暴力攻击者,因为他们必须投入大量的计算能力和时间来破解哈希密码。
举例说明
例如,Argon2 是一种现代的 KDF,它在设计时就考虑了如何对抗暴力破解攻击。它通过以下几种方式实现减慢和资源消耗:
多次迭代:Argon2 通过多次迭代哈希计算来增加计算时间。
内存硬性:需要大量内存来存储中间计算结果,这对攻击者来说增加了额外的复杂性和成本。
并行计算:支持并行计算使得合法用户在使用时能更快地完成哈希过程,但对攻击者来说却需要更高的资源投入。
这些特性使得 KDFs 在抵抗各种攻击(如暴力破解、字典攻击和彩虹表攻击)方面有显著的优势。
加盐
如果没有盐,同一个密码就会映射到相同的哈希值,这可能使黑客更容易从其哈希值中猜测密码,例如:
加盐会生成一个盐值并将其附加到每个密码中,我在下面的例子是把盐值直接附加在用户密码后,这样做就会导致同一个密码生成的哈希值为是不同的值,例如:
为了验证用户输入的密码是否正确,可以对其执行相同的过程(将该用户的盐附加到密码并计算生成的哈希值);如果结果与存储的哈希值不匹配,则输入的密码就错了。
一般在实践中,大家习惯使用已有数据(例如用户的 ID)生成盐值。如果创建了一个完全随机的盐,它就会存储在密码哈希中(例如,通过前置、附加、用它替换每 n 个字符之类的形式),方便后期验证。
再说说彩虹表
彩虹表攻击是一种利用预计算哈希值来破解密码的技术,如下图:
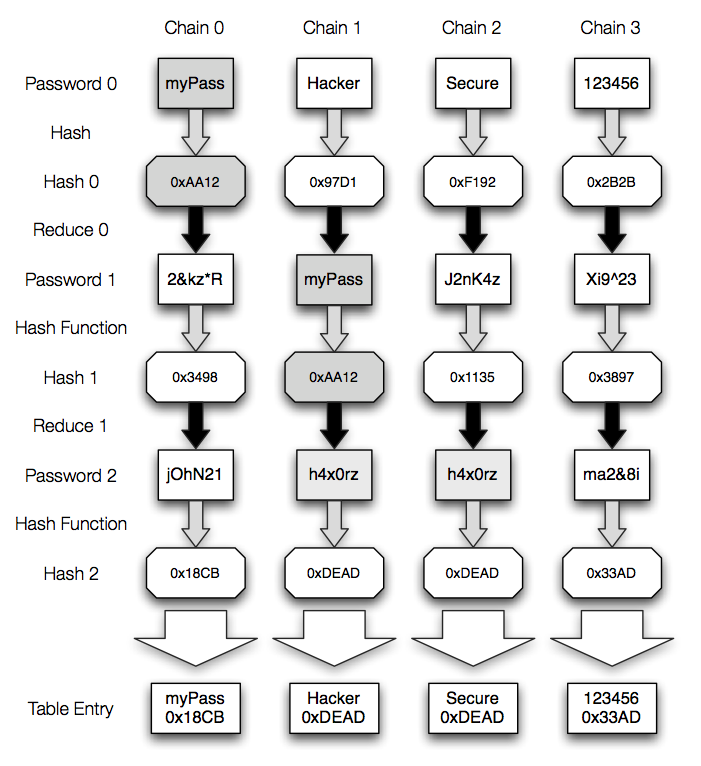 字典表
字典表
在没有彩虹表之前,攻击者会预计算所有可能的哈希值,并将这些哈希值列在一个叫做“字典表”的表中,然后,在获取目标数据库表后,通过哈希碰撞来找到对应的原始密码值。不过这个字典表一般都比较大,难以使用和存储。
彩虹表
彩虹表可以看作是“更高效版本的字典表”。它通过以下方法提高效率:
哈希函数(Hash): 用于从明文生成哈希值。
还原函数(Reduce): 用于从哈希值生成明文。
彩虹表存储多行,每行都是一个“哈希链”。每行从一个明文开始,然后多次执行 H 和 R 操作。
还原函数 Reduce
大家可能不理解,从理论上讲,从哈希值直接还原出原始密码是不可能的,那我怎么从一个SHA256的哈希还原出密码呢?这不是开玩笑吗?!
但是吧,彩虹表中的还原函数(Reduce 函数)并不是在真正意义上还原出原始密码,而是生成一个新的伪明文密码,用于继续哈希链的下一步。这也是彩虹表的巧妙之处。
示例:SHA-256 的 Reduce 函数
假设我们使用 SHA-256 来生成哈希值,我们的 Reduce 函数可以如下设计:
哈希值:
hash_value = SHA256("password123")Reduce 函数: 将哈希值的一部分转化为一个新的伪明文密码,例如从哈希值中提取前若干位,并将其转换为一个可用的密码字符串。
Reduce 函数步骤
从哈希值提取部分数据: 提取哈希值的前 N 位。例如,提取
hash_value的前 8 位。将提取的数据转化为伪明文: 使用简单的算法将提取的数据转化为字符。可以使用字符表(如 a-z, A-Z, 0-9)进行映射。
Reduce 示例
假设我们有以下哈希值(部分展示):
hash_value = "d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2"Reduce 函数可以这样操作:
提取前 8 位:
d2d2d2d2转化为伪明文:假设我们将每两位十六进制数映射到一个字符。
d2 -> 'a'd2 -> 'a'd2 -> 'a'd2 -> 'a'
生成的伪明文密码可能是 aaaa。
继续延长哈希链
通过上面的 Reduce 函数生成新的伪明文密码后,继续下一步:
新的伪明文密码:
new_password = "aaaa"哈希:
hash_value = SHA256("aaaa")再次 Reduce: 从新的哈希值中提取部分数据,再次生成新的伪明文密码。
Reduce 函数并不是逆向哈希值,而是通过一定的规则将哈希值的一部分转换为新的伪明文密码。这使得彩虹表能够在有限的存储空间内表示大量的哈希值与明文密码之间的关系,从而在攻击时有效地进行哈希碰撞检测。
为什么彩虹表在存储空间上比直接存储字典表更高效?
字典表
字典表是最简单的密码破解方法,它直接存储每个可能的明文密码及其对应的哈希值。缺点是这种方法需要存储每一个可能的组合,这会导致存储空间需求非常大。
举例:
如果我们要破解一个由6个字符组成的密码,每个字符可以是26个小写字母之一,总共有 266≈308,915,776266≈308,915,776 种可能的组合。
每个组合都需要存储其对应的哈希值,这将导致巨大的存储需求。
彩虹表
彩虹表通过“哈希链”来减少需要存储的哈希值数量。它不存储每一个可能的明文密码和对应的哈希值,而是存储经过多个哈希和还原(Reduce)操作后的链条首尾。
彩虹表的优势
彩虹表的优势在于它将每个链条中的大量中间哈希值隐式表示,而不是显式存储,从而达到显著减少存储空间的需求。
示例
假设每条链的长度为1000,以下是存储空间的比较:
字典表:存储每个明文密码和其对应的哈希值。对于 106106 个可能的明文密码,需要存储 106106 对哈希值和明文密码。
彩虹表:对于 106106 个可能的明文密码,如果每条链长度为1000,只需存储 103103 条链头和链尾。这减少了存储需求,因为每条链隐含表示了1000个哈希值和明文密码的对应关系。
彩虹表的工作原理
在实际破解过程中,攻击者会用目标哈希值尝试匹配彩虹表中的链尾。如果找到匹配项,就从对应的链头开始,通过一系列哈希和还原操作,检查是否能生成目标哈希值。如果生成成功,则破解密码,彩虹表我有空单独写一篇文章再说吧,今天星期日不想写太多东西...
为什么 MD5(或 SHA1)不能用于密码哈希?
简短回答: 抗碰撞力变弱了
MD5:2004年,MD5 被证明存在弱哈希碰撞抵抗力的问题。
SHA1:2005年也出现了类似问题,并在 2017 年被谷歌正式宣布不安全。